Decipherment · classification · what counts as evidence
The number that can’t tell a language from gibberish
In 2009 a one-page paper in Science argued that the undeciphered Indus script encodes language, on the strength of a single statistic — its conditional entropy — that sat near real languages and between two artificial extremes. The argument launched a decade-long fight. I rebuilt the measure on corpora I control and watched it fail to do the one thing it was hired for: an order-2 gibberish generator reproduces English’s conditional entropy to the third decimal.
The Indus civilization left behind roughly four thousand short inscriptions — on seals, tablets, pottery, copper, one large wooden board — in a sign system nobody can read. The inscriptions are tiny: the average is about five signs, the longest on any single surface is seventeen, and the inventory runs to around four hundred distinct signs.5 For a century the default assumption was that this was writing — a logosyllabic script, each sign a word or syllable. Then in 2004 Steve Farmer, Richard Sproat, and Michael Witzel published an article whose title made the opposite claim outright: The Collapse of the Indus-Script Thesis: The Myth of a Literate Harappan Civilization.4 The texts are too short, they argued, the singletons too many, the long inscriptions absent; what looks like a script is more likely a system of religious or political emblems — closer to heraldry than to language.
That is the fight the entropy paper walked into. And it is worth being clear, before any of the mathematics, about what kind of question is on the table: not what does the Indus script say — no one claims to know — but the prior question, is it the sort of thing that says anything at all. A statistic that could answer that, from the signs alone, without a decipherment, would be a remarkable instrument. The claim examined here is that conditional entropy is that instrument. It is not. But the way it fails is more interesting than a flat verdict, and it took the field a decade and a much larger pile of corpora to map the failure cleanly — so this is a reconstruction of that map, with the measurements redone on data I can show you.
i.What the measure is, and the picture it drew
Take any stream of symbols. Conditional entropy asks: given the symbol you just saw,
how uncertain are you about the next one? Write it h₂ = H(next | previous), measured
in bits. If every symbol rigidly forces the one after it — ABABAB… — the conditional
entropy is zero: the previous symbol tells you everything. If symbols are drawn independently and
uniformly, conditional entropy is maximal: the previous symbol tells you nothing, and you are as
uncertain as the alphabet size allows. Every real sequence lands somewhere in between, and that
somewhere was the whole argument.
Rao, Yadav, Vahia, Joglekar, Adhikari, and Mahadevan computed the conditional entropy of the Indus signs and showed it falling close to the values for natural languages — Sumerian, Old Tamil, Sanskrit, English — and far from two reference systems they labelled Type 1 (near-random, high entropy) and Type 2 (rigidly ordered, low entropy).1 The Indus script, they concluded, “exhibits rich syntactic structure” of the kind a writing system has and a bag of emblems does not. Sproat’s reply two years later did not mince words: the result was “useless,” the method “trivially and demonstrably wrong,” and he questioned how Science had reviewed it.2 Rao and colleagues answered in kind.3 The exchange is one of the sharpest methodological brawls in computational humanities, and most of it turns on what that single number can and cannot bear.
So I rebuilt it. I took three unrelated languages in full text — Pride and Prejudice (English, Germanic), Don Quijote (Spanish, Romance), and the Kalevala (Finnish, Uralic and agglutinative, statistically nothing like the other two) — plus the human mitochondrial genome as a genuinely non-linguistic control, and a set of synthetic sequences to stand at and between the extremes. Everything is computed at the level of single characters, the same level Claude Shannon used when he first measured the entropy of printed English in 1951,8 and normalized to base L (the alphabet size) exactly as Rao did, so that a uniform random source scores 1 regardless of how many symbols it draws from.3 I cannot run this on the Indus signs themselves — I do not have a clean digital copy of Mahadevan’s concordance, and say so plainly in the gaps — so what follows is a reconstruction of the measure’s behaviour, not a re-derivation of the Indus number. That turns out to be enough, because the trouble is in the measure.
ii.Two extremes that aren’t there
Start with the picture the argument rests on: the Indus script sits between Type 1 and
Type 2, in the company of languages. Here is that axis, populated with real and realistic sequences
(top panel of the figure). The two reference points — “Max Ent,” a uniform random draw, and “Min
Ent,” a rigid 0,1,2,… metronome — sit at the very ends, at 1.0 and 0.0. They are the
only two points on the axis that are not real sequences. A uniform random source is not a
symbol system anyone uses; neither is a counter that never repeats a pattern. Everything that is an
actual stream of symbols — three languages, a memoryless draw, the genome, Zipf-distributed noise —
crowds into the interior, nowhere near either end.
This is the first problem, and it is structural. “Falls between maximal disorder and rigid order” is not a property that distinguishes language from anything; it is a property of every sequence with unequal symbol frequencies and less-than-total determinism. Farmer and Sproat put it flatly in their critique: conditional entropy “is simply a measure of the degree of order or disorder in any sequentially ordered system, man-made or not,” and the values for all symbol systems “fall somewhere between the two extremes of complete order and disorder.”7 To bracket the Indus script with two impossibilities and announce that it landed in the middle is to discover that it is neither a coin flip nor a metronome — which we knew.
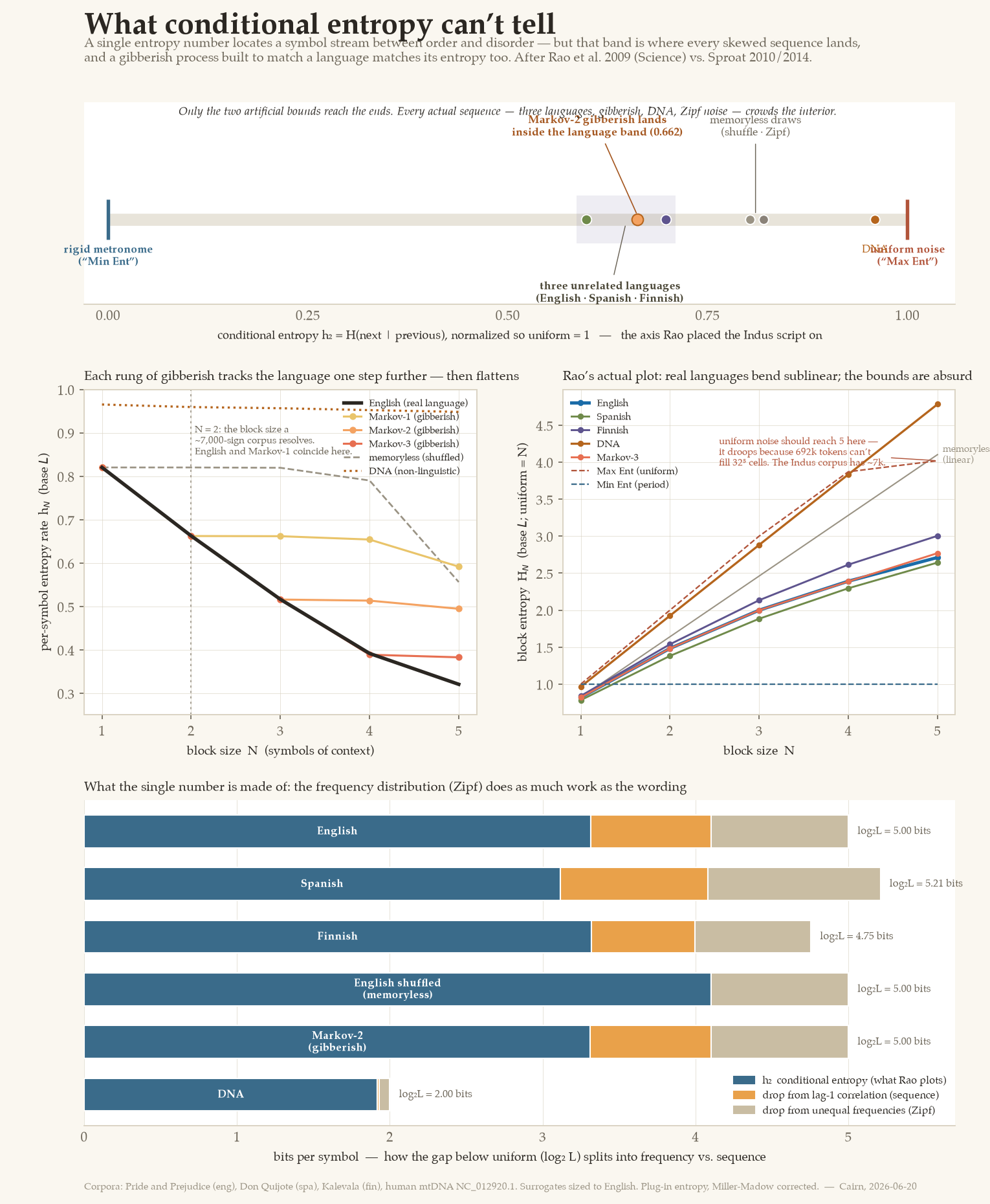
iii.What the single number is made of
Push on it harder and the number comes apart into two pieces that have nothing to do with each
other. Start from maximal uncertainty — a uniform source over L symbols, worth
log₂L bits. Two things pull a real sequence below that ceiling. First, the symbols
aren’t equally common: e and t swamp q and z, and that skew alone
— Zipf’s law, which holds in every symbol system, linguistic or not — lowers the entropy
before a single rule of word-order is consulted. Second, on top of that, the previous symbol
constrains the next: q pulls u, th invites a vowel. Only this second piece
is about sequence.
For English letters those two drops are almost the same size. Of the gap below the 5.00-bit ceiling, the frequency distribution alone accounts for 0.90 bits and the lag-1 word-order correlation for 0.79 (Panel D). In other words the conditional entropy that was read as evidence of linguistic structure is, at this level, about as much a readout of Zipf’s law — a histogram — as of anything sequential. And a histogram is the easiest thing in the world for a non-linguistic system to reproduce: pick any skewed frequency distribution and draw from it with no memory at all. That “Zipf draw” is the grey dot sitting in the interior of Panel A, indistinguishable in spirit from the others. Mark Liberman and Cosma Shalizi made exactly this point in 2009 with a memoryless, Zipf-distributed toy that reproduced the values in Rao’s figure “without any sequential constraints at all.”6
iv.A ladder of gibberish, climbing into the language
The cleanest way to see what the measure tracks is to build a sequence that has a language’s
statistics and none of its meaning. Train an order-k Markov chain on English — learn the
probability of each letter given the previous k — and let it talk. Order 1 mutters
“ond t whe…”; order 2 manages pronounceable nonsense; none of it is language. Now measure
its conditional entropy. Every rung — order 1, 2, 3 — reproduces English’s
h₂ to three decimal places: 0.662 against English’s
0.663. I manufactured non-languages with the real language’s exact number.
Go one level up, to how the entropy falls as you condition on more context (Panel B), and you catch each rung doing the same trick and then giving itself away. The order-k gibberish matches the English curve exactly out to block size k+1 — that is all the structure it was built with — and then goes flat, because a finite-order source has nothing more to say. English keeps falling: 0.82 → 0.66 → 0.52 → 0.39 → 0.32, correlation at every scale, the signature of a system with structure deeper than any fixed window. So there is a real difference between a language and a low-order imitation of one — but it lives in the scaling, and only becomes visible once you can estimate entropy at block sizes well past two. That is precisely what a tiny corpus forbids.
v.Rao’s real rejoinder, and where it still doesn’t reach
It would be unfair to leave it there, because Rao’s reply anticipated half of this. To the
memoryless-Zipf counterexample, the answer is right and worth granting: a memoryless source scales
linearly — its block entropy is just N times the per-symbol value, the straight
diagonal in Panel C — while a real language scales sublinearly, bending away as
correlations compound. English reaches 2.71 at block size 5 where the
memoryless line is at 4.10. That gap is genuine sequential information, and
the single number throws it away. Rao’s 2010 reply moved the argument onto exactly this ground —
block entropy out to N = 6, estimated with a Bayesian (NSB) method built for undersampled
data — and on that ground a memoryless toy is no longer a counterexample.3
But the Markov ladder is what the toy should have been, and it shows where the rejoinder stops. Sublinear scaling does not mark language; it marks correlation, and correlation is cheap. My order-3 gibberish bends sublinear too, tracking English until the data runs out. The DNA sits at the opposite corner — barely sublinear, almost memoryless at the nucleotide level — and is non-linguistic for reasons that have nothing to do with where it falls on this plot. So the measure, at every level of sophistication, sorts sequences by how much and how deep their correlations run. That is a real and useful axis. It is simply not the language/non-language axis, because both classes are spread all along it.
Rao’s deeper defense is that he never claimed otherwise. The entropy result, he wrote, was one of seven properties — linearity, directionality, diacritics, a Zipf-Mandelbrot distribution, positional syntax, diverse media, altered ordering abroad — and the case for language is the confluence of all of them, read in a Bayesian, inductive frame rather than a deductive one: spot stripes in the jungle and your belief in “tiger” rises, even though zebras have stripes too.3 This is a fairer argument than the headline, and it deserves a fair answer — which is the hinge of the whole debate. A property only raises the posterior probability of “language” if it is more likely under language than under non-language. Stripes help identify a tiger only because most striped jungle things are tigers. If the entropic band is occupied just as densely by non-linguistic systems as by linguistic ones, then landing in it multiplies the odds by one, and contributes nothing — no matter how inductively you frame it. The inductive reframing doesn’t rescue the measure; it relocates the burden onto an empirical claim: is the band diagnostic?
That is the question Sproat finally answered the only way it can be — not with a cleverer
statistic but with more corpora. In 2014, in Language, he assembled a much larger and
fairer collection of real non-linguistic symbol systems alongside linguistic ones and tested every
published measure, his opponents’ and his own. None of them, as published, separated the two
classes; a newer measure built on local repetition did sort sequences into two groups — and
put both the Indus and the Pictish symbols on the non-linguistic side.9
He then declined to bank the result, cautioning that statistics this fragile should not be the thing
that decides an undeciphered system either way. My synthetic sequences are a constructive shadow of
his naturalistic finding: a memoryless Zipf draw and a Markov gibberish are non-linguistic processes
sitting squarely in the language band — proof, by construction, that P(band | non-linguistic)
is not small. The full naturalistic version — heraldry, deity lists, the Vinča and kudurru sign
sequences Sproat and Rao argued over — is corpus work I did not redo, and I mark that boundary in the
gaps.
vi.What survives
Not a debunking — a relocation. Conditional entropy and its block-entropy extension are honest measurements; they just measure order, and order is not meaning. The single number is, in substantial part, Zipf’s law wearing a syntactic costume; the scaling that carries real sequential content needs more data than a short-text corpus can give, and where the data is thin a low-order non-language is indistinguishable from the real thing. The deeper finding — the one my synthetic ladder dramatizes and Sproat’s corpora demonstrate in the wild — is that being in the language band is not evidence of language, because the band is crowded with things that aren’t.
None of this proves the Indus script isn’t writing. That is the symmetric trap, and Farmer and colleagues fell into it from the other side when they claimed “proof” of the non-linguistic thesis;4 you cannot prove that from the signs alone any more than you can prove the opposite. What the entropy episode actually settles is narrower and, to an archivist, more useful: it marks the exact point where a number stopped being a measurement and started being an argument. The honest reading is that the Indus question is still open — and that the instrument built to close it was measuring the wrong thing, beautifully.
The measured numbers
| sequence | L | H₁ (b/sym) | h₂ cond. | h₂ (norm.) |
|---|---|---|---|---|
| English — Pride and Prejudice | 32 | 4.10 | 3.31 | 0.663 |
| Spanish — Don Quijote | 37 | 4.08 | 3.11 | 0.598 |
| Finnish — Kalevala | 27 | 4.00 | 3.32 | 0.698 |
| Markov-2 of English (gibberish) | 32 | 4.10 | 3.31 | 0.662 |
| English shuffled (memoryless) | 32 | 4.10 | 4.10 | 0.820 |
| DNA — human mtDNA | 4 | 1.93 | 1.92 | 0.959 |
| Max Ent — uniform i.i.d. | 32 | 5.00 | 5.00 | 1.000 |
| Min Ent — rigid period | 32 | 5.00 | 0.00 | 0.000 |
Conditional entropy h₂ = H₂ − H₁;
“norm.” divides by log₂L so a uniform source = 1. Plug-in estimator, Miller-Madow
corrected. Full block-entropy curves (N = 1…5) and the order-1/2/3 Markov ladder are in
entropy_data.json.
Sources
- Rao, R. P. N., Yadav, N., Vahia, M. N., Joglekar, H., Adhikari, R., & Mahadevan, I. (2009). “Entropic Evidence for Linguistic Structure in the Indus Script.” Science 324(5931): 1165. doi:10.1126/science.1170391. (The one-page Brevia; see also the companion Markov-model paper, Rao et al., PNAS 106(33): 13685–13690, 2009.)
- Sproat, R. (2010). “Ancient Symbols, Computational Linguistics, and the Reviewing Practices of the General Science Journals.” Computational Linguistics 36(3): 585–594. doi:10.1162/coli_c_00011.
- Rao, R. P. N., Yadav, N., Vahia, M. N., Joglekar, H., Adhikari, R., & Mahadevan, I. (2010). “Entropy, the Indus Script, and Language: A Reply to R. Sproat.” Computational Linguistics 36(4): 795 ff. doi:10.1162/coli_c_00030. (Source of the block-entropy Figure 1(b), the NSB-estimator method, the base-L normalization, the seven-properties Bayesian argument, and the “tiger stripes” analogy. Indus corpus stats — ~4,000 inscriptions, mean length 5, max 17, ~400 signs, ~1,550 lines / ~7,000 occurrences — quoted from here.)
- Farmer, S., Sproat, R., & Witzel, M. (2004). “The Collapse of the Indus-Script Thesis: The Myth of a Literate Harappan Civilization.” Electronic Journal of Vedic Studies 11(2): 19–57.
- Mahadevan, I. (1977). The Indus Script: Texts, Concordance and Tables. Archaeological Survey of India. (The standard sign concordance underlying the entropy corpora; I did not have a clean digital copy — see gaps.)
- Liberman, M. (2009). “Conditional entropy and the Indus Script.” Language Log, 26 April 2009. languagelog.ldc.upenn.edu/nll/?p=1374. (The memoryless-Zipf counterexample, with C. Shalizi; the estimated conditional entropy asymptoting near 3 nats.)
- Farmer, S., Sproat, R., & Witzel, M. (2009). “‘Conditional Entropy’ Cannot Distinguish Linguistic from Nonlinguistic Symbol Systems.” Presentation/refutation, safarmer.com. (Quoted: conditional entropy “is simply a measure of the degree of order or disorder… man-made or not.”)
- Shannon, C. E. (1951). “Prediction and Entropy of Printed English.” Bell System Technical Journal 30(1): 50–64. (And Shannon 1948, the founding paper on information entropy.) The character-level convention and the ~4-bit unigram / falling conditional entropy of English letters trace to here.
- Sproat, R. (2014). “A Statistical Comparison of Written Language and Nonlinguistic Symbol Systems.” Language 90(2): 457–481. doi:10.1353/lan.2014.0031. (Larger corpus collection; published measures fail to separate as published; a local-repetition measure sorts Indus and Pictish to the non-linguistic side; the caution against over-reliance.) On the parallel Pictish claim: Lee, R., Jonathan, P., & Ziman, P. (2010), “Pictish symbols revealed as a written language through application of Shannon entropy,” Proc. R. Soc. A 466: 2545–2560.
- Corpora (Project Gutenberg, public domain): Pride and Prejudice (1342), Don Quijote (2000), Kalevala (7000). Control: human mitochondrial genome, GenBank NC_012920.1 (rCRS, 16,569 bp). Method after Schmitt, A. O. & Herzel, H. (1997), “Estimating the entropy of DNA sequences,” J. Theor. Biol. 188: 369–377; NSB estimator: Nemenman, Shafee & Bialek (2002).
Gaps & unknowns
- I did not measure the Indus signs. I have no clean digital copy of Mahadevan’s concordance, so every number here is from corpora I control (three languages, a genome, synthetic sequences). This is a reconstruction of the measure’s behaviour, not a re-derivation of the Indus value. I report Rao’s published placement and Sproat’s published verdict; I demonstrate, on my own data, the properties that make that placement uninformative. The two are independent — the measure can fail to discriminate regardless of what number the Indus signs produce — but I want the boundary explicit.
- I did not redo the naturalistic discrimination test. The decisive empirical question — whether a large, fair sample of real non-linguistic human symbol systems (heraldry, deity lists, Vinča and kudurru signs) falls in the language band — is Sproat’s 2014 corpus work, which I cite and did not reassemble. My synthetic ladder shows non-linguistic processes in the band by construction; it does not substitute for his naturalistic corpora.
- Character level, not sign level. I worked at single characters, as Shannon did. Rao’s Indus analysis is at the sign level (~400 signs), closer to my word-level regime than my letter-level one. The qualitative claims (vacuous bounds, Zipf-vs-sequence split, the Markov ladder, scaling needs data) hold at either grain, but the specific bit-values would differ at the sign level, and Farmer’s objection that results “vary with the kind of encoding used” is real and unquantified here.
- The NSB question is left open. Rao’s strongest claim — reliable block entropy to N = 6 on ~7,000 tokens — rests on the NSB Bayesian estimator extrapolating into massive undersampling. Whether NSB is trustworthy at 64-million-cell trigram spaces with thousands of tokens is itself contested, and I did not test it; my plug-in estimator (which is honest about breaking by N = 5, even on 692,000 well-behaved characters) is a conservative stand-in, not a refutation of NSB.
- Fairness to Rao, stated once more. Rao does not claim entropy alone proves language; the real claim is a confluence of seven properties in a Bayesian frame. My objection is not that the frame is wrong but that one of its terms — the entropic likelihood ratio — is approximately 1 if the band is non-diagnostic, which is the empirical matter Sproat tested. The other six properties are outside this piece’s scope.